本文是在NEGMAS仿真软件中基于 RLBOA框架实现强化学习算法系列教程的第一篇。
NEGMAS 和 RLBOA 的简介
NEGMAS 是一个协商多代理系统的开源Python库,通过模拟商业行为,并在其上进行谈判代理的开发。类似Genius(基于Java实现的用于学术研究的谈判仿真系统)。具体请参考文档或者github仓库。
RLBOA(Reinforcement Learning,Bidding Strategy,Opponents model, Acceptance strategy)是一个用于自动谈判代理开发的强化学习框架,初始于Genius谈判系统上采用Java实现。方便实现采用不同强化学习方法进行开发的谈判代理,并可在Genius系统上进行分析和评估。
而本系列教程则是将此框架优雅的迁移到NEGMAS系统中。并为后续的强化学习算法在供应链管理中的应用研究做好相应的技术准备和铺垫,降低后续研究工作中的复杂度。
采用OpenAI开发的Gym强化学习框架,降低扩展的难度。
概念细节(RLBOA)
观察空间
此框架中可以灵活的采用多种谈判中产生的统计信息描述观察空间,比如对手和代理最后一次出价的效用(论文中采用),相对比较简单。也可以采用到帕累托边界的距离和对手的优惠度等等。同时也可以加入时间模块。
在框架RLBOA中,观察空间采用的是均匀离散化的效用空间(spaced utility bins) - 通过映射结果空间(outcome space)到其上而获得,具体的计算方式如下公式所示。
$$
ub(\omega_A^t) = \lfloor {U_A(\omega_A^t)\times N_{bins}} \rfloor \\
ub(\omega_B^t) = \lfloor {U_B(\omega_B^t)\times N_{bins}} \rfloor
$$
$U_A(.)$: 代理A的效用函数,$N_{bins}$ 是bin(一个选框,效用范围)的数目,如图1绿色框所示。
$\lfloor \rfloor$ : 下取整函数即取底符号,$\lfloor x \rfloor = \max \{n\in \mathbb{Z} \mid n\leq x \}$
$ub(\omega_A)$: RLBOA 代理的出价效用点。
结果如下图所示
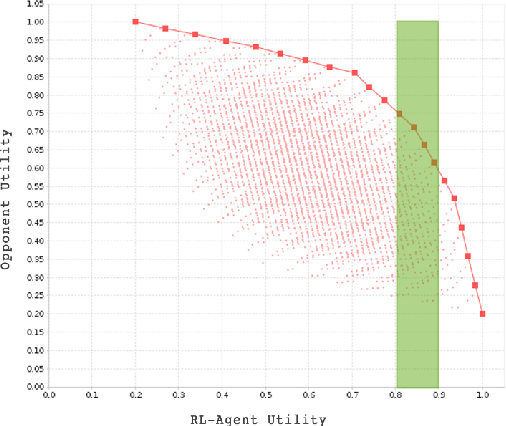
图1
观察空间则为 $$s_t = \{ub(\omega_A^t), ub(\omega_B^t), ub(\omega_A^{t-1}), ub(\omega_B^{t-1}), t \}$$
包含有四个效用点和一个时间点。
动作空间
根据离散化的观察空间即效用空间,能够得到一个离散化代理A和代理B的效用空间的对应关系图,框架的目的是在这个空间中搜寻到相对最优的出价策略,间接达到结果空间的帕累托最优。
所以动作空间的动作为上升一个bin、下降一个bin、待在原处。有一个特殊的情况,初始合同的时候,动作空间为完整的离散点空间。如果代理超过了结果空间的边界,则环境会做处反弹操作,即呆在当前点,不进行转移。另外一种情况,当选中空点时,则延当前方向,跳过该点。当RL代理选好点,对手模型会根据估计对手偏好进行出价,特殊的策略,选择最高效用点。
奖励函数
框架中可以采用自定义的奖励函数,非常自然的想法,奖励可以是合同的效用。根据代理的目的可以采用其他的方式,例如基于时间和社会福利的效用函数等等,可以对效用函数做一些调整,修改下最后的奖励信息,将多种因素也作为最后的考量加入到奖励信号中。
优化方法
优化方法的算法实现不包含在Gym Env的设计中,为强化学习算法的实现部分,在这里就不作具体说明,会在完成Gym Env设计后,基于RLBOA框架实现强化学习的算法中做详细解释。
Gym Env 设计
在了解了RLBOA框架中需要在Gym Env 设计中对应实现的基本概念后,就可以开始 Env 的具体实现,Env 的名字暂定为 RLBOANegmasNegotiation, 版本为v0。实现过程可以分为空间、环境核心、Negmas接口、通用功能、测试。
空间实现
观察空间,考虑到观察空间采用的是离散效用值,所以可以直接通过继承gym.spaces.Discrete 来实现,未出价时的观察空间需要一个特殊的符号标记(无法直接采用0,0代表的是第一个效用bin),所以需要加入 no_op 函数,返回一个特殊的标记,这里可以设为 None。
示例代码如下:
1 | import gym |
动作空间:考虑动作空间(up, down, stay)单个动作也为离散值(0,1)表示是否选中,可以设计一个dict空间,配合离散空间,用以表示动作空间。
示例代码如下:
1 | import gym |
总结空间设计,其实采用的都为线性空间对单个参数进行表述,RLBOA 框架设计之除就考虑到了空间的数值表示,兼容不同强化学习算法的实现和训练。
本篇主要是介绍了下Negmas,RLBOA,Gym的基本概念和空间设计的基本代码,是一篇概述型的文章,作为后面实现的理论基础,推荐仔细阅读。引用链接下的文章里面有详细的介绍,如果有迷惑,强烈推荐阅读。同时也为Gym Env的设计做了方向的规划。
下一篇: 继续实现Gym Env的余下部分
相关引用
RLBOA: A Modular Reinforcement Learning Framework forAutonomous Negotiating Agents
Jasper Bakker, Aron Hammond, Daan Bloembergen, Tim Baarslag
Genius
Official Website
Genius: An Integrated Environment for Supporting the Design of Generic Automated Negotiators
RAZLIN,1SARITKRAUS,1,2TIMBAARSLAG,3DMYTROTYKHONOV,3KOENHINDRIKS,3ANDCATHOLIJNM. JONKER3
Written with StackEdit.